后缀数组简介 一些约定 字符串相关的定义请参考 字符串基础 .
字符串下标从 1 1
字符串 𝑠 s 𝑛 n
" 后缀 𝑖 i 𝑖 i 𝑖 i 𝑠 s 𝑠 [ 𝑖 … 𝑛 ] s [ i … n ]
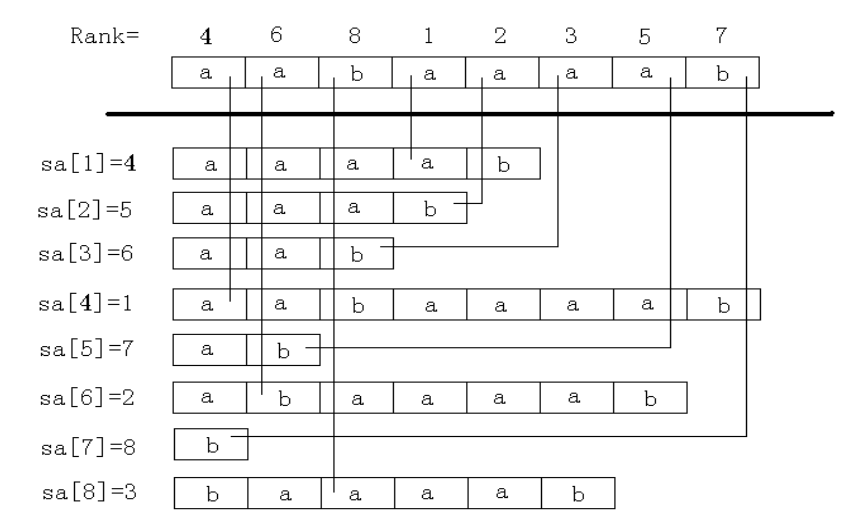
后缀数组是什么? 后缀数组(Suffix Array)主要关系到两个数组:𝑠 𝑎 s a 𝑟 𝑘 r k
其中,𝑠 𝑎 [ 𝑖 ] s a [ i ] 𝑖 i 𝑠 𝑎 s a
𝑟 𝑘 [ 𝑖 ] r k [ i ] 𝑖 i 𝑟 𝑘 r k
这两个数组满足性质:𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] ] = 𝑟 𝑘 [ 𝑠 𝑎 [ 𝑖 ] ] = 𝑖 s a [ r k [ i ] ] = r k [ s a [ i ] ] = i
解释 后缀数组示例:
后缀数组怎么求? O(n^2logn) 做法 相信这个做法大家还是能自己想到的:将盛有全部后缀字符串的数组进行 sort 排序,由于排序进行 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n ) 𝑂 ( 𝑛 ) O ( n ) 𝑂 ( 𝑛 2 l o g 𝑛 ) O ( n 2 log n )
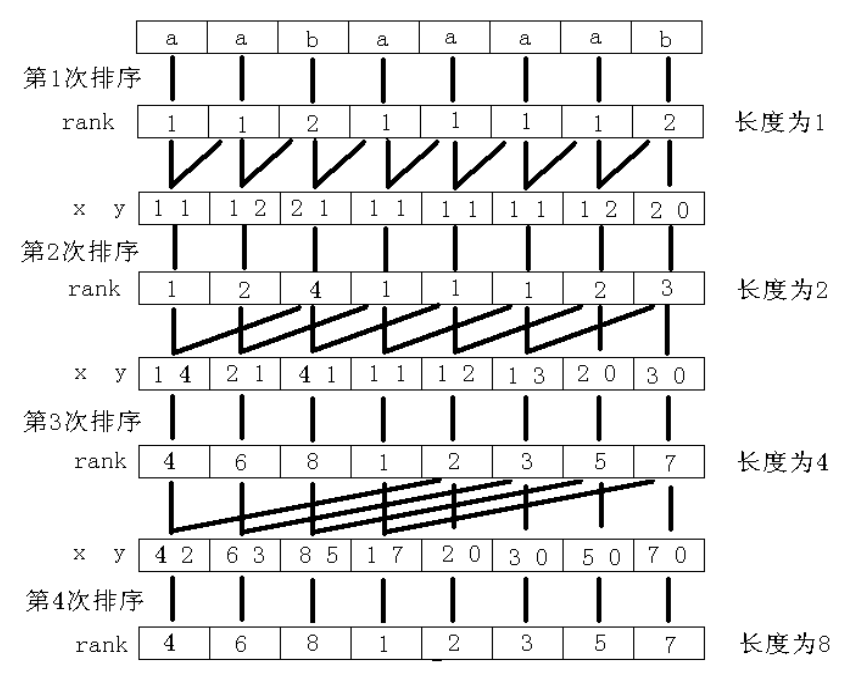
O(nlog^2n) 做法 这个做法要用到倍增的思想.
首先对字符串 𝑠 s 1 1 𝑠 𝑎 1 s a 1 𝑟 𝑘 1 r k 1
倍增过程:
用两个长度为 1 1 𝑟 𝑘 1 [ 𝑖 ] r k 1 [ i ] 𝑟 𝑘 1 [ 𝑖 + 1 ] r k 1 [ i + 1 ] 𝑠 s 2 2 { 𝑠 [ 𝑖 … m i n ( 𝑖 + 1 , 𝑛 ) ] | 𝑖 ∈ [ 1 , 𝑛 ] } { s [ i … min ( i + 1 , n ) ] | i ∈ [ 1 , n ] } 𝑠 𝑎 2 s a 2 𝑟 𝑘 2 r k 2
之后用两个长度为 2 2 𝑟 𝑘 2 [ 𝑖 ] r k 2 [ i ] 𝑟 𝑘 2 [ 𝑖 + 2 ] r k 2 [ i + 2 ] 𝑠 s 4 4 { 𝑠 [ 𝑖 … m i n ( 𝑖 + 3 , 𝑛 ) ] | 𝑖 ∈ [ 1 , 𝑛 ] } { s [ i … min ( i + 3 , n ) ] | i ∈ [ 1 , n ] } 𝑠 𝑎 4 s a 4 𝑟 𝑘 4 r k 4
以此倍增,用长度为 𝑤 / 2 w / 2 𝑟 𝑘 𝑤 / 2 [ 𝑖 ] r k w / 2 [ i ] 𝑟 𝑘 𝑤 / 2 [ 𝑖 + 𝑤 / 2 ] r k w / 2 [ i + w / 2 ] 𝑠 s 𝑤 w 𝑠 [ 𝑖 … m i n ( 𝑖 + 𝑤 − 1 , 𝑛 ) ] s [ i … min ( i + w − 1 , n ) ] 𝑠 𝑎 𝑤 s a w 𝑟 𝑘 𝑤 r k w 𝑖 + 𝑤 > 𝑛 i + w > n 𝑟 𝑘 𝑤 [ 𝑖 + 𝑤 ] r k w [ i + w ]
𝑟 𝑘 𝑤 [ 𝑖 ] r k w [ i ] 𝑠 [ 𝑖 … 𝑖 + 𝑤 − 1 ] s [ i … i + w − 1 ] 𝑤 ⩾ 𝑛 w ⩾ n 𝑠 𝑎 𝑤 s a w
过程 倍增排序示意图:
显然倍增的过程是 𝑂 ( l o g 𝑛 ) O ( log n ) sort 对子串进行排序是 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n ) 2 2
除此之外,每次倍增在 sort 排序完后,还有额外的 𝑂 ( 𝑛 ) O ( n ) 𝑟 𝑘 r k 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n )
所以这个算法的时间复杂度就是 𝑂 ( 𝑛 l o g 2 𝑛 ) O ( n log 2 n )
实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43 #include <algorithm>
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std ;
constexpr int N = 1000010 ;
char s [ N ];
int n , w , sa [ N ], rk [ N << 1 ], oldrk [ N << 1 ];
// 为了防止访问 rk[i+w] 导致数组越界,开两倍数组.
// 当然也可以在访问前判断是否越界,但直接开两倍数组方便一些.
int main () {
int i , p ;
scanf ( "%s" , s + 1 );
n = strlen ( s + 1 );
for ( i = 1 ; i <= n ; ++ i ) sa [ i ] = i , rk [ i ] = s [ i ];
for ( w = 1 ; w < n ; w <<= 1 ) {
sort ( sa + 1 , sa + n + 1 , []( int x , int y ) {
return rk [ x ] == rk [ y ] ? rk [ x + w ] < rk [ y + w ] : rk [ x ] < rk [ y ];
}); // 这里用到了 lambda
memcpy ( oldrk , rk , sizeof ( rk ));
// 由于计算 rk 的时候原来的 rk 会被覆盖,要先复制一份
// 若两个子串相同,它们对应的 rk 也需要相同,所以要去重
for ( p = 0 , i = 1 ; i <= n ; ++ i ) {
if ( oldrk [ sa [ i ]] == oldrk [ sa [ i - 1 ]] &&
oldrk [ sa [ i ] + w ] == oldrk [ sa [ i - 1 ] + w ]) {
rk [ sa [ i ]] = p ;
} else {
rk [ sa [ i ]] = ++ p ;
}
}
}
for ( i = 1 ; i <= n ; ++ i ) printf ( "%d " , sa [ i ]);
return 0 ;
}
O(nlogn) 做法 在刚刚的 𝑂 ( 𝑛 l o g 2 𝑛 ) O ( n log 2 n ) 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n ) 𝑂 ( 𝑛 ) O ( n ) 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n )
前置知识:计数排序 ,基数排序 .
由于计算后缀数组的过程中排序的关键字是排名,值域为 𝑂 ( 𝑛 ) O ( n ) 𝑂 ( 𝑛 ) O ( n )
实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61 #include <algorithm>
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std ;
constexpr int N = 1000010 ;
char s [ N ];
int n , sa [ N ], rk [ N << 1 ], oldrk [ N << 1 ], id [ N ], cnt [ N ];
int main () {
int i , m , p , w ;
scanf ( "%s" , s + 1 );
n = strlen ( s + 1 );
m = 127 ;
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ i ] = s [ i ]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ i ]] -- ] = i ;
memcpy ( oldrk + 1 , rk + 1 , n * sizeof ( int ));
for ( p = 0 , i = 1 ; i <= n ; ++ i ) {
if ( oldrk [ sa [ i ]] == oldrk [ sa [ i - 1 ]]) {
rk [ sa [ i ]] = p ;
} else {
rk [ sa [ i ]] = ++ p ;
}
}
for ( w = 1 ; w < n ; w <<= 1 , m = n ) {
// 对第二关键字:id[i] + w进行计数排序
memset ( cnt , 0 , sizeof ( cnt ));
memcpy ( id + 1 , sa + 1 ,
n * sizeof ( int )); // id保存一份儿sa的拷贝,实质上就相当于oldsa
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ id [ i ] + w ]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ id [ i ] + w ]] -- ] = id [ i ];
// 对第一关键字:id[i]进行计数排序
memset ( cnt , 0 , sizeof ( cnt ));
memcpy ( id + 1 , sa + 1 , n * sizeof ( int ));
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ id [ i ]]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ id [ i ]]] -- ] = id [ i ];
memcpy ( oldrk + 1 , rk + 1 , n * sizeof ( int ));
for ( p = 0 , i = 1 ; i <= n ; ++ i ) {
if ( oldrk [ sa [ i ]] == oldrk [ sa [ i - 1 ]] &&
oldrk [ sa [ i ] + w ] == oldrk [ sa [ i - 1 ] + w ]) {
rk [ sa [ i ]] = p ;
} else {
rk [ sa [ i ]] = ++ p ;
}
}
}
for ( i = 1 ; i <= n ; ++ i ) printf ( "%d " , sa [ i ]);
return 0 ;
}
一些常数优化 如果你把上面那份代码交到 LOJ #111: 后缀排序 上:
这是因为,上面那份代码的常数的确很大.
第二关键字无需计数排序 思考一下第二关键字排序的实质,其实就是把超出字符串范围(即 𝑠 𝑎 [ 𝑖 ] + 𝑤 > 𝑛 s a [ i ] + w > n 𝑠 𝑎 [ 𝑖 ] s a [ i ] 𝑠 𝑎 s a
int cur = 0 ;
for ( int i = n - w + 1 ; i <= n ; i ++ ) id [ ++ cur ] = i ;
for ( int i = 1 ; i <= n ; i ++ )
if ( sa [ i ] > w ) id [ ++ cur ] = sa [ i ] - w ;
优化计数排序的值域 每次对 𝑟 𝑘 r k 𝑝 p 𝑝 p 𝑟 𝑘 r k
若排名都不相同可直接生成后缀数组 考虑新的 𝑟 𝑘 r k [ 1 , 𝑛 ] [ 1 , n ]
实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50 #include <algorithm>
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std ;
constexpr int N = 1000010 ;
char s [ N ];
int n ;
int m , p , rk [ N * 2 ], oldrk [ N ], sa [ N * 2 ], id [ N ], cnt [ N ];
int main () {
scanf ( "%s" , s + 1 );
n = strlen ( s + 1 );
m = 128 ;
for ( int i = 1 ; i <= n ; i ++ ) cnt [ rk [ i ] = s [ i ]] ++ ;
for ( int i = 1 ; i <= m ; i ++ ) cnt [ i ] += cnt [ i - 1 ];
for ( int i = n ; i >= 1 ; i -- ) sa [ cnt [ rk [ i ]] -- ] = i ;
for ( int w = 1 ;; w <<= 1 , m = p ) { // m = p 即为值域优化
int cur = 0 ;
for ( int i = n - w + 1 ; i <= n ; i ++ ) id [ ++ cur ] = i ;
for ( int i = 1 ; i <= n ; i ++ )
if ( sa [ i ] > w ) id [ ++ cur ] = sa [ i ] - w ;
memset ( cnt , 0 , sizeof ( cnt ));
for ( int i = 1 ; i <= n ; i ++ ) cnt [ rk [ i ]] ++ ;
for ( int i = 1 ; i <= m ; i ++ ) cnt [ i ] += cnt [ i - 1 ];
for ( int i = n ; i >= 1 ; i -- ) sa [ cnt [ rk [ id [ i ]]] -- ] = id [ i ];
p = 0 ;
memcpy ( oldrk , rk , sizeof ( oldrk ));
for ( int i = 1 ; i <= n ; i ++ ) {
if ( oldrk [ sa [ i ]] == oldrk [ sa [ i - 1 ]] &&
oldrk [ sa [ i ] + w ] == oldrk [ sa [ i - 1 ] + w ])
rk [ sa [ i ]] = p ;
else
rk [ sa [ i ]] = ++ p ;
}
if ( p == n ) break ; // p = n 时无需再排序
}
for ( int i = 1 ; i <= n ; i ++ ) printf ( "%d " , sa [ i ]);
return 0 ;
}
O(n) 做法 在一般的题目中,常数较小的倍增求后缀数组是完全够用的,求后缀数组以外的部分也经常有 𝑂 ( 𝑛 l o g 𝑛 ) O ( n log n )
但如果遇到特殊题目、时限较紧的题目,或者是你想追求更短的用时,就需要学习 𝑂 ( 𝑛 ) O ( n )
SA-IS 可以参考 诱导排序与 SA-IS 算法 ,另外它的 评论页面 也有参考价值.
DC3 可以参考[2009] 后缀数组——处理字符串的有力工具 by. 罗穗骞 .
后缀数组的应用 寻找最小的循环移动位置 将字符串 𝑆 S 𝑆 𝑆 S S
例题:「JSOI2007」字符加密 .
在字符串中找子串 任务是在线地在主串 𝑇 T 𝑆 S 𝑇 T 𝑆 S 𝑇 T 𝑆 S 𝑆 S 𝑇 T 𝑇 T 𝑝 p 𝑆 S 𝑆 S 𝑂 ( | 𝑆 | ) O ( | S | ) 𝑂 ( | 𝑆 | l o g | 𝑇 | ) O ( | S | log | T | ) 𝑇 T 𝑝 p
从字符串首尾取字符最小化字典序 例题:「USACO07DEC」Best Cow Line .
题意:给你一个字符串,每次从首或尾取一个字符组成字符串,问所有能够组成的字符串中字典序最小的一个.
题解 暴力做法就是每次最坏 𝑂 ( 𝑛 ) O ( n )
由于需要在原串后缀与反串后缀构成的集合内比较大小,可以将反串拼接在原串后,并在中间加上一个没出现过的字符(如 #,代码中可以直接使用空字符),求后缀数组,即可 𝑂 ( 1 ) O ( 1 )
参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51 #include <cctype>
#include <cstring>
#include <iostream>
using namespace std ;
constexpr int N = 1000010 ;
char s [ N ];
int n , sa [ N ], id [ N ], oldrk [ N * 2 ], rk [ N * 2 ], px [ N ], cnt [ N ];
bool cmp ( int x , int y , int w ) {
return oldrk [ x ] == oldrk [ y ] && oldrk [ x + w ] == oldrk [ y + w ];
}
int main () {
int i , w , m = 200 , p , l = 1 , r , tot = 0 ;
cin >> n ;
r = n ;
for ( i = 1 ; i <= n ; ++ i )
while ( cin >> s [ i ], ! isalpha ( s [ i ]));
for ( i = 1 ; i <= n ; ++ i )
rk [ i ] = rk [ 2 * n + 2 - i ] = s [ i ]; // 拼接正反两个字符串,中间空出一个字符
n = 2 * n + 1 ;
// 求后缀数组
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ i ]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ i ]] -- ] = i ;
for ( w = 1 ; w < n ; w *= 2 , m = p ) { // m=p 就是优化计数排序值域
for ( p = 0 , i = n ; i > n - w ; -- i ) id [ ++ p ] = i ;
for ( i = 1 ; i <= n ; ++ i )
if ( sa [ i ] > w ) id [ ++ p ] = sa [ i ] - w ;
memset ( cnt , 0 , sizeof ( cnt ));
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ px [ i ] = rk [ id [ i ]]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ px [ i ]] -- ] = id [ i ];
memcpy ( oldrk , rk , sizeof ( rk ));
for ( p = 0 , i = 1 ; i <= n ; ++ i )
rk [ sa [ i ]] = cmp ( sa [ i ], sa [ i - 1 ], w ) ? p : ++ p ;
}
// 利用后缀数组O(1)进行判断
while ( l <= r ) {
cout << ( rk [ l ] < rk [ n + 1 - r ] ? s [ l ++ ] : s [ r -- ]);
if (( ++ tot ) % 80 == 0 ) cout << '\n' ; // 回车
}
return 0 ;
}
height 数组 LCP(最长公共前缀) 两个字符串 𝑆 S 𝑇 T 𝑥 x 𝑥 ≤ m i n ( | 𝑆 | , | 𝑇 | ) x ≤ min ( | S | , | T | ) 𝑆 𝑖 = 𝑇 𝑖 ( ∀ 1 ≤ 𝑖 ≤ 𝑥 ) S i = T i ( ∀ 1 ≤ i ≤ x )
下文中以 𝑙 𝑐 𝑝 ( 𝑖 , 𝑗 ) l c p ( i , j ) 𝑖 i 𝑗 j
height 数组的定义 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑖 ] = 𝑙 𝑐 𝑝 ( 𝑠 𝑎 [ 𝑖 ] , 𝑠 𝑎 [ 𝑖 − 1 ] ) h e i g h t [ i ] = l c p ( s a [ i ] , s a [ i − 1 ] ) 𝑖 i
ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 1 ] h e i g h t [ 1 ] 0 0
O(n) 求 height 数组需要的一个引理 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 ] ] ≥ ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] − 1 h e i g h t [ r k [ i ] ] ≥ h e i g h t [ r k [ i − 1 ] ] − 1
证明 当 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] ≤ 1 h e i g h t [ r k [ i − 1 ] ] ≤ 1 0 0
当 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] > 1 h e i g h t [ r k [ i − 1 ] ] > 1
根据 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 h e i g h t 𝑙 𝑐 𝑝 ( 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] , 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 − 1 ] − 1 ] ) = ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] > 1 l c p ( s a [ r k [ i − 1 ] ] , s a [ r k [ i − 1 ] − 1 ] ) = h e i g h t [ r k [ i − 1 ] ] > 1
既然后缀 𝑖 − 1 i − 1 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 − 1 ] − 1 ] s a [ r k [ i − 1 ] − 1 ] ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] h e i g h t [ r k [ i − 1 ] ]
那么不妨用 𝑎 𝐴 a A 𝑎 a 𝐴 A ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] − 1 h e i g h t [ r k [ i − 1 ] ] − 1
那么后缀 𝑖 − 1 i − 1 𝑎 𝐴 𝐷 a A D 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 − 1 ] − 1 ] s a [ r k [ i − 1 ] − 1 ] 𝑎 𝐴 𝐵 a A B 𝐵 < 𝐷 B < D 𝐵 B 𝐷 D
进一步地,后缀 𝑖 i 𝐴 𝐷 A D 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 − 1 ] − 1 ] + 1 s a [ r k [ i − 1 ] − 1 ] + 1 𝐴 𝐵 A B
因为后缀 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] − 1 ] s a [ r k [ i ] − 1 ] 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] ] s a [ r k [ i ] ] 𝑖 i 𝐴 𝐵 < 𝐴 𝐷 A B < A D
所以 𝐴 𝐵 ⩽ A B ⩽ 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] − 1 ] < 𝐴 𝐷 s a [ r k [ i ] − 1 ] < A D 𝑖 i 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] − 1 ] s a [ r k [ i ] − 1 ] 𝐴 A
于是就可以得出 𝑙 𝑐 𝑝 ( 𝑖 , 𝑠 𝑎 [ 𝑟 𝑘 [ 𝑖 ] − 1 ] ) l c p ( i , s a [ r k [ i ] − 1 ] ) ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] − 1 h e i g h t [ r k [ i − 1 ] ] − 1 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 ] ] ≥ ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑟 𝑘 [ 𝑖 − 1 ] ] − 1 h e i g h t [ r k [ i ] ] ≥ h e i g h t [ r k [ i − 1 ] ] − 1
O(n) 求 height 数组的代码实现 利用上面这个引理暴力求即可:
for ( i = 1 , k = 0 ; i <= n ; ++ i ) {
if ( rk [ i ] == 0 ) continue ;
if ( k ) -- k ;
while ( s [ i + k ] == s [ sa [ rk [ i ] - 1 ] + k ]) ++ k ;
height [ rk [ i ]] = k ;
}
𝑘 k 𝑛 n 𝑛 n 2 𝑛 2 n 𝑂 ( 𝑛 ) O ( n )
height 数组的应用 两子串最长公共前缀 𝑙 𝑐 𝑝 ( 𝑠 𝑎 [ 𝑖 ] , 𝑠 𝑎 [ 𝑗 ] ) = m i n { ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑖 + 1 . . 𝑗 ] } l c p ( s a [ i ] , s a [ j ] ) = min { h e i g h t [ i + 1. . j ] }
感性理解:如果 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 h e i g h t
严格证明可以参考[2004] 后缀数组 by. 许智磊 .
有了这个定理,求两子串最长公共前缀就转化为了 RMQ 问题 .
比较一个字符串的两个子串的大小关系 假设需要比较的是 𝐴 = 𝑆 [ 𝑎 . . 𝑏 ] A = S [ a . . b ] 𝐵 = 𝑆 [ 𝑐 . . 𝑑 ] B = S [ c . . d ]
若 𝑙 𝑐 𝑝 ( 𝑎 , 𝑐 ) ≥ m i n ( | 𝐴 | , | 𝐵 | ) l c p ( a , c ) ≥ min ( | A | , | B | ) 𝐴 < 𝐵 ⟺ | 𝐴 | < | 𝐵 | A < B ⟺ | A | < | B |
否则,𝐴 < 𝐵 ⟺ 𝑟 𝑘 [ 𝑎 ] < 𝑟 𝑘 [ 𝑐 ] A < B ⟺ r k [ a ] < r k [ c ]
不同子串的数目 子串就是后缀的前缀,所以可以枚举每个后缀,计算前缀总数,再减掉重复.
「前缀总数」其实就是子串个数,为 𝑛 ( 𝑛 + 1 ) / 2 n ( n + 1 ) / 2
如果按后缀排序的顺序枚举后缀,每次新增的子串就是除了与上一个后缀的 LCP 剩下的前缀.这些前缀一定是新增的,否则会破坏 𝑙 𝑐 𝑝 ( 𝑠 𝑎 [ 𝑖 ] , 𝑠 𝑎 [ 𝑗 ] ) = m i n { ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑖 + 1 . . 𝑗 ] } l c p ( s a [ i ] , s a [ j ] ) = min { h e i g h t [ i + 1. . j ] }
所以答案为:
𝑛 ( 𝑛 + 1 ) 2 − 𝑛 ∑ 𝑖 = 2 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑖 ] n ( n + 1 ) 2 − ∑ i = 2 n h e i g h t [ i ]
出现至少 k 次的子串的最大长度 例题:「USACO06DEC」Milk Patterns .
题解 出现至少 𝑘 k 𝑘 k
所以,求出每相邻 𝑘 − 1 k − 1 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 h e i g h t
可以使用单调队列 𝑂 ( 𝑛 ) O ( n )
参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 #include <cstring>
#include <iostream>
#include <set>
using namespace std ;
constexpr int N = 40010 ;
int n , k , a [ N ], sa [ N ], rk [ N ], oldrk [ N ], id [ N ], px [ N ], cnt [ 1000010 ], ht [ N ], ans ;
multiset < int > t ; // multiset 是最好写的实现方式
bool cmp ( int x , int y , int w ) {
return oldrk [ x ] == oldrk [ y ] && oldrk [ x + w ] == oldrk [ y + w ];
}
int main () {
cin . tie ( nullptr ) -> sync_with_stdio ( false );
int i , j , w , p , m = 1000000 ;
cin >> n >> k ;
-- k ;
for ( i = 1 ; i <= n ; ++ i ) cin >> a [ i ]; // 求后缀数组
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ i ] = a [ i ]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ i ]] -- ] = i ;
for ( w = 1 ; w < n ; w <<= 1 , m = p ) {
for ( p = 0 , i = n ; i > n - w ; -- i ) id [ ++ p ] = i ;
for ( i = 1 ; i <= n ; ++ i )
if ( sa [ i ] > w ) id [ ++ p ] = sa [ i ] - w ;
memset ( cnt , 0 , sizeof ( cnt ));
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ px [ i ] = rk [ id [ i ]]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ px [ i ]] -- ] = id [ i ];
memcpy ( oldrk , rk , sizeof ( rk ));
for ( p = 0 , i = 1 ; i <= n ; ++ i )
rk [ sa [ i ]] = cmp ( sa [ i ], sa [ i - 1 ], w ) ? p : ++ p ;
}
for ( i = 1 , j = 0 ; i <= n ; ++ i ) { // 求 height
if ( j ) -- j ;
while ( a [ i + j ] == a [ sa [ rk [ i ] - 1 ] + j ]) ++ j ;
ht [ rk [ i ]] = j ;
}
for ( i = 1 ; i <= n ; ++ i ) { // 求所有最小值的最大值
t . insert ( ht [ i ]);
if ( i > k ) t . erase ( t . find ( ht [ i - k ]));
ans = max ( ans , * t . begin ());
}
cout << ans ;
return 0 ;
}
是否有某字符串在文本串中至少不重叠地出现了两次 可以二分目标串的长度 | 𝑠 | | s | ℎ h | 𝑠 | | s | | 𝑠 | | s |
连续的若干个相同子串 我们可以枚举连续串的长度 | 𝑠 | | s | | 𝑠 | | s | [2009] 后缀数组——处理字符串的有力工具 .
例题:「NOI2016」优秀的拆分 .
结合并查集 某些题目求解时要求你将后缀数组划分成若干个连续 LCP 长度大于等于某一值的段,亦即将 ℎ h ℎ h
经典题目:「NOI2015」品酒大会
结合线段树 某些题目让你求满足条件的前若干个数,而这些数又在后缀排序中的一个区间内.这时我们可以用归并排序的性质来合并两个结点的信息,利用线段树维护和查询区间答案.
结合单调栈 例题:「AHOI2013」差异
题解 被加数的前两项很好处理,为 𝑛 ( 𝑛 − 1 ) ( 𝑛 + 1 ) / 2 n ( n − 1 ) ( n + 1 ) / 2 𝑛 − 1 n − 1 𝑛 ( 𝑛 + 1 ) / 2 n ( n + 1 ) / 2
我们知道 𝑙 𝑐 𝑝 ( 𝑖 , 𝑗 ) = 𝑘 l c p ( i , j ) = k m i n { ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑖 + 1 . . 𝑗 ] } = 𝑘 min { h e i g h t [ i + 1. . j ] } = k 𝑙 𝑐 𝑝 ( 𝑖 , 𝑗 ) l c p ( i , j ) m i n { 𝑥 | 𝑖 + 1 ≤ 𝑥 ≤ 𝑗 , ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 [ 𝑥 ] = 𝑙 𝑐 𝑝 ( 𝑖 , 𝑗 ) } min { x | i + 1 ≤ x ≤ j , h e i g h t [ x ] = l c p ( i , j ) }
考虑每个位置对答案的贡献是哪些后缀的 LCP,其实就是从它开始向左若干个连续的 ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 h e i g h t ℎ 𝑒 𝑖 𝑔 ℎ 𝑡 h e i g h t 单调栈 计算.
单调栈部分类似于 Luogu P2659 美丽的序列 以及 悬线法 .
参考代码 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65 #include <cstring>
#include <iostream>
#include <string>
using namespace std ;
constexpr int N = 500010 ;
string s ;
int n , sa [ N ], rk [ N << 1 ], oldrk [ N << 1 ], id [ N ], px [ N ], cnt [ N ], ht [ N ], sta [ N ],
top , l [ N ];
long long ans ;
bool cmp ( int x , int y , int w ) {
return oldrk [ x ] == oldrk [ y ] && oldrk [ x + w ] == oldrk [ y + w ];
}
int main () {
int i , k , w , p , m = 300 ;
cin >> s ;
n = s . size ();
s = " " + s ;
ans = 1l l * n * ( n - 1 ) * ( n + 1 ) / 2 ;
// 求后缀数组
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ rk [ i ] = s [ i ]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ rk [ i ]] -- ] = i ;
for ( w = 1 ; w < n ; w <<= 1 , m = p ) {
for ( p = 0 , i = n ; i > n - w ; -- i ) id [ ++ p ] = i ;
for ( i = 1 ; i <= n ; ++ i )
if ( sa [ i ] > w ) id [ ++ p ] = sa [ i ] - w ;
memset ( cnt , 0 , sizeof ( cnt ));
for ( i = 1 ; i <= n ; ++ i ) ++ cnt [ px [ i ] = rk [ id [ i ]]];
for ( i = 1 ; i <= m ; ++ i ) cnt [ i ] += cnt [ i - 1 ];
for ( i = n ; i >= 1 ; -- i ) sa [ cnt [ px [ i ]] -- ] = id [ i ];
memcpy ( oldrk , rk , sizeof ( rk ));
for ( p = 0 , i = 1 ; i <= n ; ++ i )
rk [ sa [ i ]] = cmp ( sa [ i ], sa [ i - 1 ], w ) ? p : ++ p ;
}
// 求 height
for ( i = 1 , k = 0 ; i <= n ; ++ i ) {
if ( k ) -- k ;
while ( s [ i + k ] == s [ sa [ rk [ i ] - 1 ] + k ]) ++ k ;
ht [ rk [ i ]] = k ;
}
// 维护单调栈
for ( i = 1 ; i <= n ; ++ i ) {
while ( ht [ sta [ top ]] > ht [ i ]) -- top ; // top类似于一个指针
l [ i ] = i - sta [ top ];
sta [ ++ top ] = i ;
}
// 最后利用单调栈算 ans
sta [ ++ top ] = n + 1 ;
ht [ n + 1 ] = -1 ;
for ( i = n ; i >= 1 ; -- i ) {
while ( ht [ sta [ top ]] >= ht [ i ]) -- top ;
ans -= 2l l * ht [ i ] * l [ i ] * ( sta [ top ] - i );
sta [ ++ top ] = i ;
}
cout << ans ;
return 0 ;
}
类似的题目:「HAOI2016」找相同字符 .
习题 参考资料 本页面中(4070a9b 引入的部分)主要译自博文 Суффиксный массив 与其英文翻译版 Suffix Array .其中俄文版版权协议为 Public Domain + Leave a Link;英文版版权协议为 CC-BY-SA 4.0.
论文:
[2004] 后缀数组 by. 许智磊
[2009] 后缀数组——处理字符串的有力工具 by. 罗穗骞
2026/6/20 23:34:20 ,更新历史 在 GitHub 上编辑此页! Ir1d , ksyx , Tiphereth-A , Early0v0 , ouuan , countercurrent-time , StudyingFather , H-J-Granger , NachtgeistW , CCXXXI , Enter-tainer , hsfzLZH1 , minghu6 , AngelKitty , Chrogeek , cjsoft , diauweb , ezoixx130 , GekkaSaori , Henry-ZHR , HeRaNO , iamtwz , Konano , LovelyBuggies , Makkiy , Marcythm , mgt , P-Y-Y , PotassiumWings , SamZhangQingChuan , sshwy , Suyun514 , weiyong1024 , alphagocc , billchenchina , Clouder0 , Eletary , gavinliu266 , GavinZhengOI , Gesrua , gi-b716 , Great-designer , hly1204 , Hukeqing , ImpleLee , interestingLSY , Joob1n , kenlig , kxccc , lailai0916 , LingeZ3z , lychees , Menci , Nanarikom , Peanut-Tang , r-value , renbaoshuo , SukkaW , TOMWT-qwq , WAAutoMaton , werner-yin , yafngzh , yjl9903 , zirnc CC BY-SA 4.0 和 SATA